Stacy Konkiel
Professional Data Wrangler 🤠
Biography
I develop data analysis and visualization approaches to help organizations understand their influence, benchmark against their peers, and perform competitive analyses. In my spare time, I work on natural language processing challenges. I co-founded the HuMetricsHSS initiative and Metrics Toolkit. Previously, I worked with teams at Altmetric, Our Research (Impactstory), Indiana University & PLOS.
Interests
- Data engineering
- Natural language processing
- Climate justice
- Data for the public good
Education
-
Certificate in Data Visualization and Analytics, 2020
University of Minnesota, School of Continuing Education
-
MIS in Information Science, 2008
Indiana University
-
MLS in Library Science, 2008
Indiana University
-
BA in English Literature, 2006
University of Delaware
Recent Posts

Projects
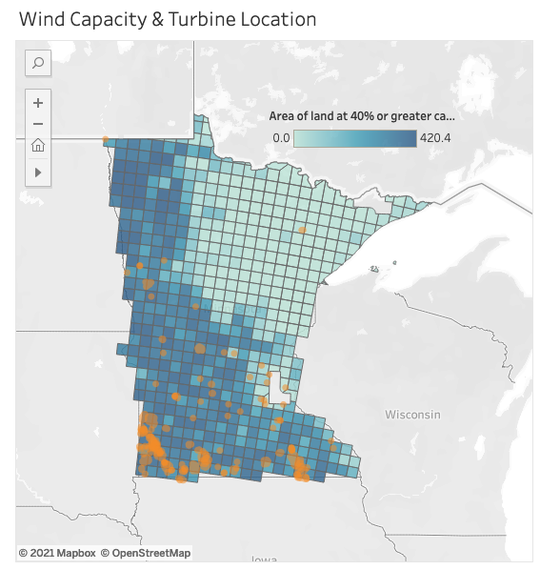
A Tableau dashboard that explores the state’s most-used renewable energy source and maps strategic opportunities.
A resource for researchers and evaluators that provides guidance for demonstrating and evaluating claims of research impact.

Co-founder and co-PI from 2016-2019. Rethinking how to accurately measure research impact in the humanities and social sciences.

Talks


Recent Publications
(2020).
The transformative power of values-enacted scholarship.
Humanities and Social Sciences Communications.
(2020).
Assessing the Impact and Quality of Research Data Using Altmetrics and Other Indicators.
Scholarly Assessment Reports.
(2020).
Dimensions: Bringing down barriers between scientometricians and data.
Quantitative Science Studies.
(2018).
Metrics Toolkit: an online evidence-based resource for navigating the research metrics landscape.
Journal of the Medical Library Association.